Experiments with LLM's - Large scale natural language data extraction
tldr
When working on another project, I wanted a way of using an LLM to get answers from Spreadsheets. When the project was started (Autumn 2024) I was sort of disappointed with the limitations in place.
This is mainly as all the data is loaded into context and that is (currently) limited. Tables inherently have a structure, so I was interesested in seeing if you could use this structure to get better results.
Below is an approach to combining the power of LLM’s while de-coupling it from the size of data.
What?
A proof of concept of using a large language model (LLM) to generate a bespoke “transformation machine” that uses an LLM to generate a series of “transform steps” to turn natural language into computation.
What follows is a description of a concrete example and implementation, I will return the the more general question later on. Specific problem: What I want is ability to ask natural language questions of tabular data and reliably get back accurate results over large datasets.
A working example for the IMDB dataset coming soon
Why?
We want to have the best of both worlds, combine the ability to ask questions in a natural way; with the computation accuracy and efficiency of computation.
We want to be able to ask questions of data without having to write SQL queries or load the data into a database.
We want to be able to ask questions directly of data, even if that data is incomplete or badly formatted.
Lets take the example of the IMDB dataset (1 million+ rows) for example (https://www.kaggle.com/datasets/octopusteam/full-imdb-dataset?resource=download). We might want to find a movie set in a particlar location from a particular time period with a certain rating.
| ID | Title | Type | Genres | Rating | Votes | Year |
|---|---|---|---|---|---|---|
| tt0000009 | Miss Jerry | movie | Romance | 5.4 | 215 | 1894 |
| tt0000147 | The Corbett-Fitzsimmons Fight | movie | Documentary, News, Sport | 5.2 | 539 | 1897 |
| tt0000502 | Bohemios | movie | 4.4 | 18 | 1905 | |
| tt0000574 | The Story of the Kelly Gang | movie | Action, Adventure, Biography | 6.0 | 941 | 1906 |
How would we do this currently?
- We could manually read through the table finding things that look interesting - given the table has over 1 million rows, this could be slow.
- We could load the data into a database and write a SQL query to get the data we want - perhaps if this is a common task and it proves worth the effort.
- Load the Data into an LLM and ask the AI the question - this can work, however it has some disadvantages. LLM’s have limited context windows, they can make mistakes and they can be slow. (More below)
We want the best of all worlds, and it is possible to have it, with the right approach. Turning natural language questions into fast computable steps that can be run on the data directly.
System in action
How?
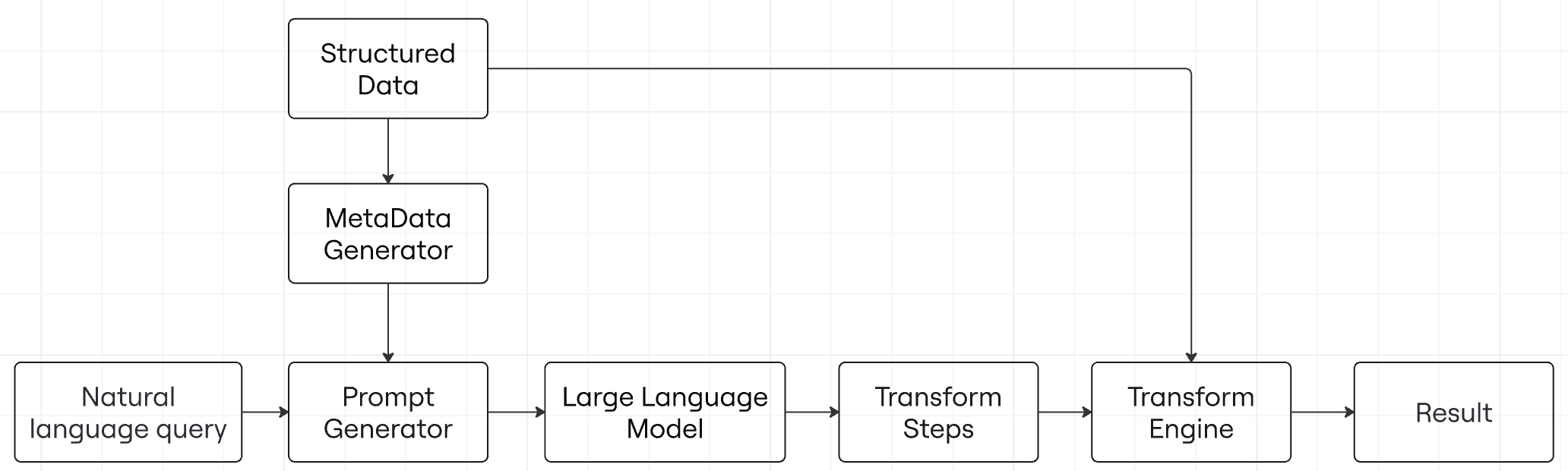
The process is roughly:
- Metadata Generation: We programmatically inspect the structured data source and create metadata — information about columns, their types, and structure.
- LLM Generation of Steps: We feed the LLM the natural language query, the metadata, and carefully crafted instructions. Instead of asking it for the final answer, we ask it to produce a set of transformation steps. For example, if you say, “Get me all customers in Europe,” the LLM might produce a filter step that includes a list of European countries.
- Execution on the Data: Another engine (like a Python script with Pandas) runs these transformation steps on the data. If a step fails—say, dates are in inconsistent formats—we can feed those problematic rows back to the LLM and fix them.
- Result: The output is a clean, final subset of data or an answer. The LLM only generated the instructions, so it’s not slowed down or confused by huge datasets.
A DSL for Intelligence
I claim that table extraction is just one example of an application of using a LLM to generate accurate, computable steps from natural language. These steps can be designed to better use the AI’s generation capabilites, producing not an answer, but in effect a custom program for a specific question and data source.
These steps can be built up one by one to define certain capabilites on the data, such as filtering, sorting, grouping, joining, etc. They do not have to be complete or complex, so you avoid the challenge of understanding a complete DSL such as SQL or AWK.
Predefined instructions are carefully crafted to leverage the AI model’s natural language understanding capabilities, resulting in transformation rules that are:
- More intuitive, flexible, and robust to variations in data structure and query semantics compared to traditional DSL approaches such as directly generating Structured Query Language (SQL) commands.
- We can disconnect the generation of rules from the size of the data. The system outlined here works in the same way for 10 rows or 10 million rows.
- Better leverage the capabilities of the models to generate the correct rules. (Robustly reproduced, easy to debug each step)
- Has some surprising results. Such as semantic expansion, such as asking a customer table for every customer in Europe returns a step with -
["United Kingdom", "Germany", "France", "Italy", "Spain", "Netherlands", "Greece", "Sweden", "Poland", "Belgium", "Finland", "Denmark", "Ireland", "Portugal", "Austria", "Hungary", "Czech Republic", "Romania", "Bulgaria", "Slovakia", "Croatia", "Estonia", "Slovenia", "Latvia", "Lithuania", "Luxembourg", "Malta", "Cyprus"] - Because of the interaction of LLM and computation, it can also provide error correcting and data cleaning steps. Because we can robustly infer type information we can use computation to find data that cannot be converted to a type, and feed this back into the LLM to fix the errors. For example - we infer “signup_date” is a date, but some rows have dates formatted as ISO8601 and some as “4th Feb, 2024”. We can use computation to EXTRACT the rows that are not valid dates and feed this back into the LLM to fix the errors (updating the original data).
What is happening?
In the worked example, we are effectively creating a compression of the data, we enter a natural language question and data, and we get back a compressed version of the data. That could be a final answer or a part of a larger pipeline that feeds into other computations or a LLM to reach a final answer.
Transform Steps
One of the key ideas behind this PoC is the generation of transform steps. The ideal properties of these steps:
- Can be robustly generated from a LLM - this means designed from the ground up to work with what LLM’s do well.
- Expressed as well formed JSON (or equivalent format) that can be used as input to computation
- Steps are expressive enough to achieve the intended outcome
The set of rules define what operations can be performed, they could be a pure extraction machine, or any set of operations the author wants to provide to the user. There is an open question between the complexity of operations and ultimate performance. A most optimal set of rules is open question.
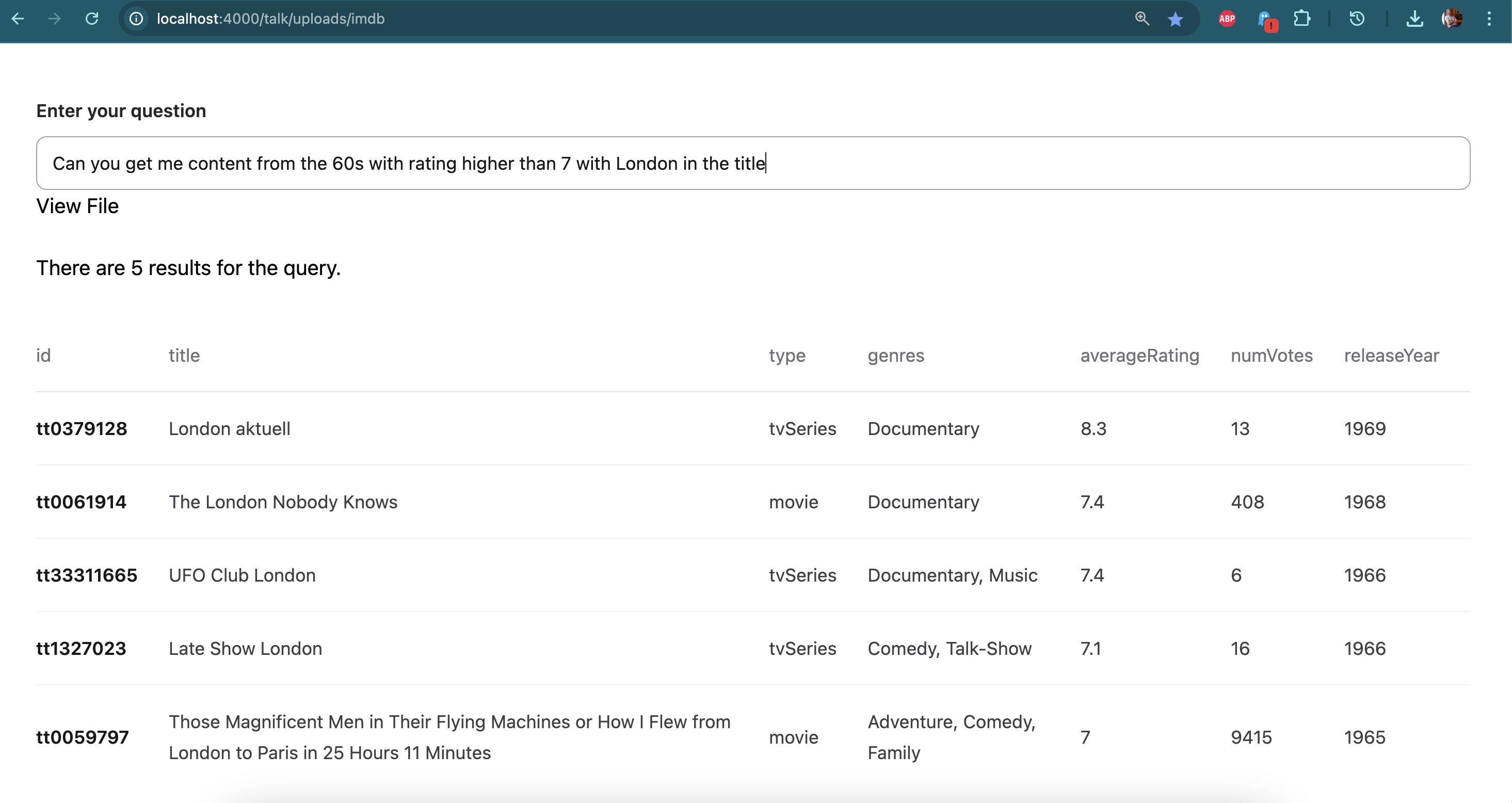
Below are the transform steps generated from asking the question “Can you get me content from the 60s with rating higher than 7 with London in the title” to the IMDB table.
[
{
"column_index": 6,
"column_type": "int",
"from": 1960,
"method": "filter_row_by_range",
"to": 1969
},
{
"column_index": 4,
"column_type": "float",
"from": 7,
"method": "filter_row_by_range",
"to": null
},
{
"filters": [
"London"
],
"method": "filter_row",
"row_index": 1
}
]
This list of steps is passed to a transform engine along with the data to produce a result. This meaning the same steps are applied no matter the size of the data.
Semantic Expansion
One of the surprising moments for me when designing this PoC, when inspecting the generated steps, was something I call semantic expansion. This is using the knowledge of the LLM to better answer ambiguous questions. For example, having a customer table with country of origin, but we want to know something that is not explicitly in the data, such as the idea of Europe. The LLM can expand Europe into a list of countries.
Error Correction
As part of the transform steps we ask the LLM to imply the type of the data (int, date, etc). Using this information we can then attempt to convert the data into that type. We can extract all values that cannot be converted (due to bad formatting) these values can be fed back to the LLM to correct the formatting errors, correcting the data.
[
"2020-02-25 - on a thursday",
"25-02-2020",
"1st October, 2022",
"11/11/24",
"Thursday, 25th February 2021",
"2020-02-25"
] => [
"2020-02-25",
"2020-02-25",
"2022-10-01",
"2024-11-11",
"2021-02-25",
"2020-02-25"
]
Why not just use a LLM?
While Large Language Models are increasingly capable of handling larger datasets and performing complex analyses, there are several fundamental limitations that make a hybrid approach more practical, advantages over using a LLM directly:
1. Computational Efficiency
- LLMs process entire datasets token by token, making them inefficient for large-scale data operations
- A single query on a million-row dataset could cost hundreds of dollars in API fees
- Traditional computational methods (like indexed searches) are orders of magnitude faster
2. Reliability and Reproducibility
- LLMs are inherently probabilistic, potentially giving different answers to the same question
- The transformation steps approach generates deterministic operations that can be verified and will always produce the same results
- Error handling becomes explicit rather than hidden in the LLM’s black box
3. Resource Management
- Context window limitations still exist even in modern LLMs
- Processing large datasets requires chunking and managing complex prompt engineering
- Our approach maintains constant LLM resource usage regardless of dataset size
4. Debugging and Maintenance
- When an LLM makes a mistake, it’s often unclear why or how to fix it
- With transformation steps, each operation is explicit and can be individually tested
- The system can be gradually improved by refining the step generation process
5. Caching and Optimization
- Similar queries can reuse cached transformation steps
- Common patterns can be optimized without requiring new LLM calls
- Intermediate results can be stored and reused
6. Data Privacy and Security
- Direct LLM use requires sending entire datasets to external APIs
- Our approach only shares metadata and transformation logic
- Sensitive data remains within your computational environment
7. Cost Scaling
- LLM API costs scale with dataset size
- In our approach, LLM costs remain constant regardless of data volume
- Computation costs scale linearly with traditional optimization techniques available
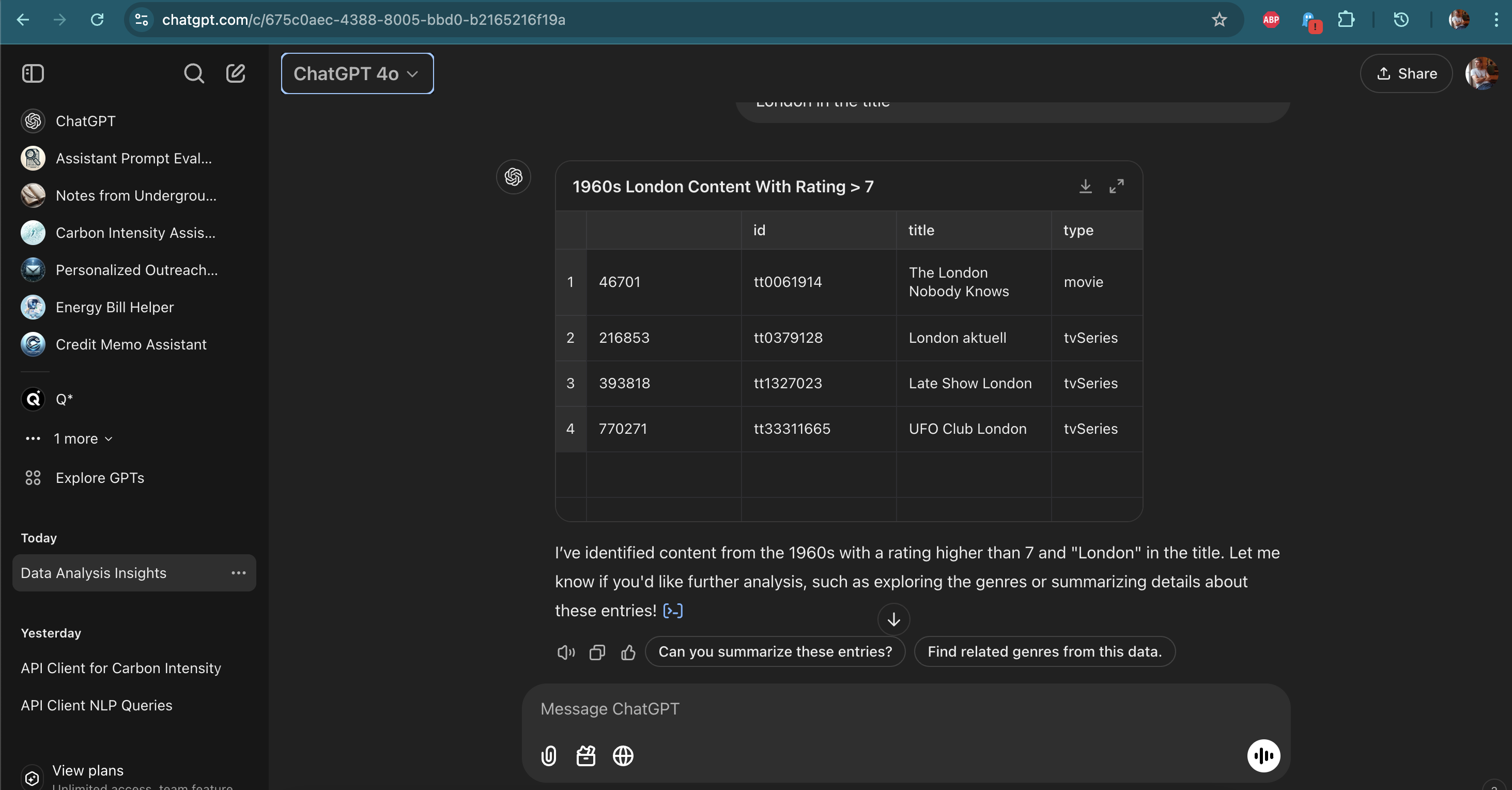
Side by Side comparison GPT-4o vs TableAI:
FaQs
Example of natural language queries
"Can you get me films from the 60s with rating higher than 7 with London in the title"
"Can I get name and email from the last 5 customers from Europe"
"Can you get me all the info for customers who joined between 2021 and 2023"
Example table from IMDB data
| ID | Title | Type | Genres | Rating | Votes | Year |
|---|---|---|---|---|---|---|
| tt0000009 | Miss Jerry | movie | Romance | 5.4 | 215 | 1894 |
| tt0000147 | The Corbett-Fitzsimmons Fight | movie | Documentary, News, Sport | 5.2 | 539 | 1897 |
| tt0000502 | Bohemios | movie | 4.4 | 18 | 1905 | |
| tt0000574 | The Story of the Kelly Gang | movie | Action, Adventure, Biography | 6.0 | 941 | 1906 |
Why not use SQL?
SQL is powerful but requires technical expertise and a proper database setup. This approach offers several advantages:
- Natural language accessibility - users don’t need to learn SQL syntax
- Works directly with raw data files without database setup
- Handles messy or inconsistent data through LLM-assisted cleaning
- Provides semantic understanding (like automatically knowing European countries) that SQL alone cannot provide
- Can work with data sources that aren’t easily imported into SQL databases
How is this different from ToolFormer / Tool use?
While both approaches involve LLMs interacting with tools, this system is distinct because:
- It generates transformation steps rather than directly executing commands
- The steps are composable and reusable
- It separates the “thinking” phase (LLM generating steps) from the “execution” phase (computing on data)
- It can handle arbitrary-sized datasets since the LLM only sees metadata and generates instructions
- The transformation steps can be cached and optimized, unlike direct tool calls
What about data privacy and security?
Since the LLM only sees metadata and sample problematic rows (not the full dataset), this approach can be more privacy-preserving than sending entire datasets to an LLM. The actual computation happens locally or in your secure environment.
How does it handle ambiguous queries?
The system can:
- Generate clarifying steps when needed
- Use semantic understanding to expand ambiguous terms (like “Europe” → list of countries)
- Return multiple possible interpretations of the query for user confirmation
- Include validation steps in the transformation pipeline
What are the performance implications?
The hybrid approach offers several performance benefits:
- Only calls the LLM once to generate steps, not for processing data
- Can cache commonly used transformation patterns
- Executes computations using efficient data processing libraries
- Scales linearly with data size since LLM involvement is constant
How reliable are the generated transformations?
The system improves reliability by:
- Using predefined step types that are known to work
- Allowing validation and testing of steps before execution
- Providing error correction for data quality issues
- Enabling human review of generated steps when needed
- Supporting iterative refinement of problematic transformations
What about maintaining and debugging?
The transformation steps provide several advantages for maintenance:
- Steps are explicit and can be logged
- Each step can be tested independently
- Problems can be isolated to specific transformations
- Steps can be version controlled and reviewed
- The system can generate documentation for the transformations
How does it handle complex data relationships?
Based on the metadata, the system can:
- Understand relationships between different data sources
- Generate appropriate join operations
- Maintain data integrity through the transformation pipeline
- Handle nested and hierarchical data structures
Future work
- Fine-tuning: We currently use off-the-shelf base models. Training a model specifically for this task might yield even better, more reliable transformation steps.
- Optimized Instructions: Right now, we have a small set of rules. There’s an opportunity to refine these instructions to produce more robust and complex transformations.
- Other Domains: This approach isn’t limited to tables. Anywhere you have structured or semi-structured data—like logs or certain configuration formats—you could potentially apply the same pattern.